
For those venturing into large language models, the acronym RAG may have piqued your interest – it stands for retrieval augmented generation. But why this sudden surge in RAG’s popularity? The answer lies in its ability to address some of the inherent shortcomings of large language models. This machine learning approach seamlessly marries the intrinsic capabilities of large language models (LLMs) with external knowledge and information retrieval systems. Instead of solely depending on the pre-existing knowledge of an LLM, the RAG pattern ventures beyond, fetching pertinent external information to enrich responses with a newfound level of context and accuracy.
Unmasking the Limitations of LLMs
Many of us have delved into the world of Large Language Models (LLMs) through platforms like Chat-GPT. With extended usage, you might have discerned certain limitations beyond occasional peculiar responses. The foremost rule is the confinement to training data, as vividly depicted in the short image below.
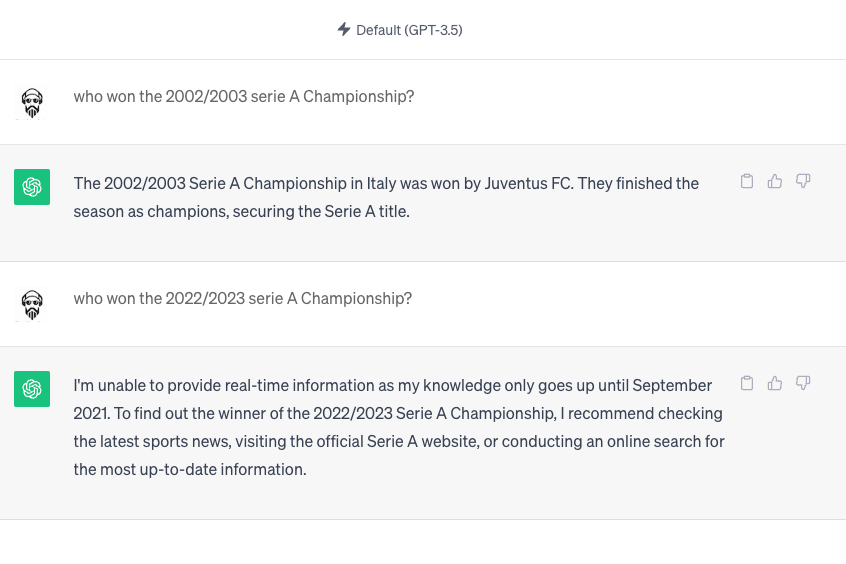
As the scenario illustrates, when I asked about the 2022/2023 Serie A Championship winner, Chat-GPT couldn’t immediately respond. It pointed out that its knowledge was last updated in September 2021, while the championship occurred in 2023. But what if we could keep it updated in real time?
In our conversation, I tried to introduce current information by including the latest sports news about the 2022/2023 sports events, and I just repeated the question. Here, we encountered a standard limitation with language models: contextual constraints. Chat-GPT informed me that the message exceeded the maximum context length, a known challenge when working with these models.

In conclusion, we are currently encountering two issues. The model is unable to retrieve information beyond September 2021, and the token limit is restricting our ability to provide up-to-date information to the model.
How can we overcome those specific issues?
Let’s use the previous example and ask a new question: who won the 200m at the Zurich Weltklasse Diamond League in 2023? To overcome contextual constraints, we will build an external knowledge base. We can create a sports results database from September 2021 onwards and save the information in a vectorized database. (e.g. Pinecone). We can then develop an intelligent system to retrieve and send contextual information to the LLM to ensure it always receives accurate information.
The system is called Retrieval Augmented Generation (RAG) in plain text. It works similarly to the method I explained in this chart:
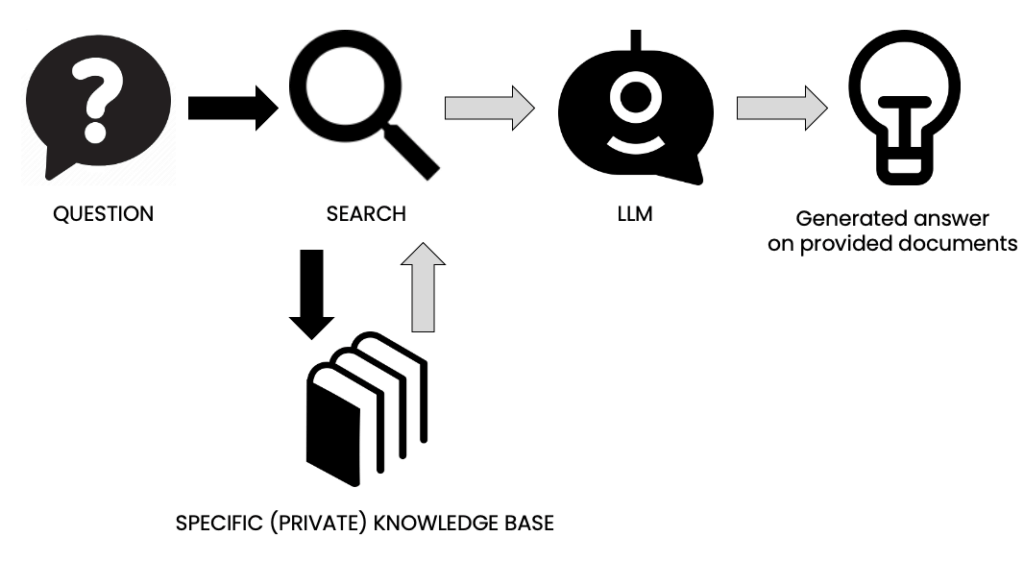

Deciphering Retrieval Augmented Generation (RAG)
RAG represents a strategy to enhance the capabilities of LLMs by enabling them to search and retrieve information from a knowledge base. This knowledge base could include corporate documents, news archives, or non-LLM data.
A RAG pipeline can be broken down into three components (see Figure 2):
- The knowledge base is transformed into a vectorized format, simplifying search and retrieval.
- A tool comprising a retriever and a question-answering model. The retriever identifies relevant information from the knowledge base through similarity searches, addressing the context window issue by providing concise, pertinent context. The question-answering model then processes this truncated context to respond to queries.
- An LLM powers an agent with access to the tool. While not mandatory, an agent proves valuable for tackling more complex questions, as it can employ reasoning frameworks like ReAct. The agent serves as an intermediary, assessing whether the tool has successfully retrieved relevant information and answered the original question.
Why is RAG important for developing business applications that are connected to LLM?
In essence, RAG bridges the gap between general-purpose language models and the specific needs of businesses, enabling the creation of tailored applications that leverage the vast knowledge available on the internet and within organizations. This makes RAG a valuable tool for companies looking to harness the power of language models to solve real-world problems and gain a competitive edge.
Retrieval Augmented Generation (RAG) is highly relevant for building business applications connected to Large Language Models (LLMs) due to several key advantages:
- Access to Proprietary Knowledge: Many businesses have proprietary data, documents, and information crucial to their operations. RAG allows LLMs to tap into this proprietary knowledge, creating applications that can provide insights and answers based on an organization’s internal documents and data.
- Real-time Updates: Business environments are dynamic, and updating the latest information is essential. RAG enables LLMs to retrieve real-time data and information from external sources, such as news feeds or databases, ensuring that the applications remain relevant and accurate.
- Customization for Specific Domains: Businesses often operate in specialized domains with their terminology and nuances. RAG can be fine-tuned and customized to understand and respond to domain-specific queries and requirements, making it a valuable tool for creating domain-specific business applications.
- Improved Decision Support: Business applications powered by RAG can assist in decision-making processes by providing contextually rich information and insights. This can be particularly valuable in market analysis, risk assessment, and strategy development.
- Efficient Customer Support: RAG can enhance customer support by enabling chatbots and virtual assistants to access a wider knowledge base, answer complex queries, and provide more personalized assistance to customers, improving the overall customer experience.
- Compliance and Risk Management: In regulated industries, businesses must adhere to specific guidelines and compliance requirements. RAG can assist in accessing and interpreting relevant regulatory documents, helping companies to remain compliant and manage risks effectively.
- Transparency and Accountability: RAG-based applications can provide citations or references to the sources of information they use, promoting transparency and accountability. This is essential in situations where accurate information and citations are critical, such as legal or financial contexts.
- Cost-Effective Solutions: Instead of investing in developing entirely new language models for specific business applications, RAG allows organizations to leverage existing LLMs and enhance them with external knowledge sources. This approach can be more cost-effective and efficient.
Exploring RAG’s Boundaries
Following this discussion thus far, you might have concluded that RAG is a panacea. However, responsible practitioners must acknowledge its limitations. Assessing the performance of RAG-enabled LLMs can be challenging due to their composite nature. A pragmatic approach involves evaluating each component (retrieval and question answering) separately, though their interplay complicates matters. A weak retrieval component invariably diminishes the question-answering component’s performance.
Constructing evaluation datasets can also prove intricate. RAG applications involving proprietary business documents may require bespoke datasets, as more than pre-existing ones might be needed.
Recognizing that no system is flawless, even when evaluation is accurate, is crucial. Would you happen to know how we can address this for RAG-based applications? The consensus among engineers I’ve consulted is to offer a transparent user interface (UI). RAG-based applications are evolving to provide responses, citations, or references to the knowledge base sections they draw upon. This additional context empowers users to discern the reliability of their RAG application’s responses.
In Conclusion
RAG emerges as an affordable and straightforward method to enhance LLMs and mitigate their inherent limitations. Nevertheless, the practical implementation of RAG-enabled models demands careful evaluation. Thoughtful attention to user interface and user experience is essential to ensure that users receive sufficient context to evaluate the reliability of their RAG-enabled models’ responses.